Traditionally, the SET is one of the most widely employed instruments in higher education for evaluating the quality of teaching (e.g., Hendry & Dean, 2002; Hounsell, 2003). For a typical SET, after taking a course, students are asked to rate various aspects of the course (e.g., the clarity of the objectives, the usefulness of the materials, the methods of assessment) on a Likert scale. SET data is often the first and foremost source of information that individual teachers can use to evaluate both existing and new innovative teaching practices. SETs are often integrated in higher education professional development activities. For instance, at some faculties at Leiden university at Leiden University, SET results and their interpretation is an integral part of the University Teacher Qualification (a.k.a., BKO). Starting out teachers are expected to critically reflect in teaching portfolios on the results of SETs for the classes they have taught. Furthermore, the results of SETs can function as a source of information for teachers’ supervisors to guide discussions in yearly Performance and Development Interviews, sometimes leading to recommended or enforced future professional development activities for teachers.
However, for some time now, the SET has been subject to scrutiny for a variety of reasons. First, based on an up-to-date meta-analysis, the validity of SETs seems questionable. That is, there appears to be no apparent correlation between SET scores and student learning performance at the end of a course (Uttl, 2017). In fact, when learning performance is operationalized as the added value of a teacher to the later performance of students during subsequent courses (Kornell & Hausman, 2016), the relationship can even be inversed (i.e., teachers with lower SET scores appear to be of more added value). One explanation for this finding is that making a course more difficult and challenging can result in lower SET scores, presenting teachers with a perverse incentive to lower the bar for their students to obtain higher scores on a SET (Stroebe, 2020).
Second, the intensive and frequent use of SETs can lead to a form of “evaluation fatigue” among students (Hounsell, 2003), sometimes resulting in mindless and unreliable evaluations of teaching (e.g., Reynolds, 1977; Uijtdehaage & O’Neal, 2015). As a case in point, a classic article by Reynolds (1977) reported how a vast majority of students in a medical course chose to evaluate a lecture that had been cancelled, as well as a video that was no longer part of the course. In a rather ironic reflection on these results Reynolds concluded that:
“As students become sufficiently skilled in evaluating films and lectures without being there,… …, then there would be no need to wait until the end of the semester to fill out evaluations. They could be completed during the first week of class while the students are still fresh and alert.”
Third, the results of student evaluations of teaching can be severely biased (e.g., Neath, 1996; Heffernan, 2022). For instance, in a somewhat tongue-in-cheek review of the literature, Neath (1996) listed 20 tips for teachers to improve their evaluations without having to improve their actual teaching. The first tip on the list: Be male. Apparently, research suggests that, in general, male teachers receive higher ratings on SETs compared to female teachers. In a more recent review of the literature, Heffernan (2022) goes on to argue that SETs can be subject to racist, sexist and homophobic prejudices, and biased against discipline and subject area. Also, SETs that also allow for a qualitative response can sometimes illicit abusive comments most often directed towards women and teachers from marginalized groups. As such, SETs can be a cause of stress and anxiety for teachers rather than being an actual aid to their development.
Fourth, although studies often emphasize the importance of SETs for supporting and improving the quality of education, the underlying mechanism remains elusive (Harrison et al., 2022). It is unclear how SETs contribute to improving the quality of teaching. To the contrary, teachers can often find it challenging to decide what actual changes to make based on aggregated SET data that is largely quantitative in nature (Henry & Dean, 2010).
In short, the continued use of SETs for evaluating the quality of teaching in higher education is difficult to justify. The findings reported in the literature indicate that the validity and reliability of the SET are questionable, and the value for educational practice appears to be limited. One could argue that sticking with the SET is more a tradition than it is evidence-informed practice. Perhaps universities mostly persist in the routine in lack of an equally (cost-)efficient and scalable alternative. In this blog, we delineate the development and pilot of one possible alternative.
The FET. Late 2023, an Innovation Fund Proposal was awarded a small grant to develop an alternative approach for the evaluation of teaching. At the start of 2024, Mario de Jonge (researcher at ICLON), Boje Moers (project manager at LLInC), Anthea Aerts (educational consultant at LLInC), Erwin Veenstra, and Arian Kiandoost (developers/data analysts, LLInC) collaborated on the development and subsequent small-scale pilot of the FET (Formative Evaluation of Teaching).
The FET is designed to be more conducive for the improvement of teaching practices (formative, qualitative) and less focused on mere assessment of teaching (summative, quantitative). Like the traditional SET, the FET is fast, efficient and relatively inexpensive. However, the FET aims to give teachers clearer directions and qualitative input on how to improve their teaching.
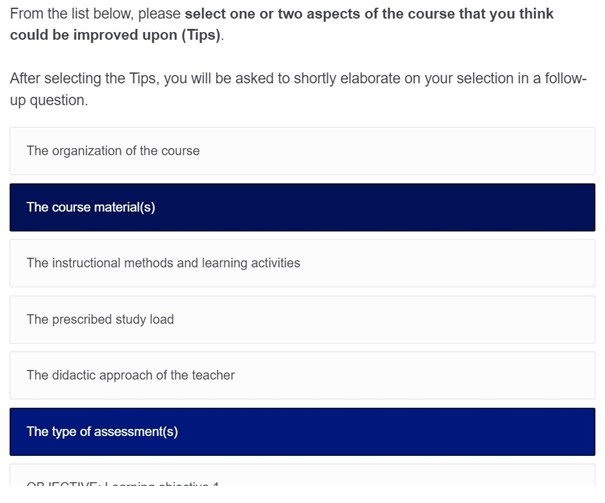
In the first step of the FET survey (Figure 1), students are presented with a list of course aspects on which they can give feedback. Some of the aspects on the list are general (e.g., the methods of assessment), while some of them can be course-specific (e.g., learning objectives). Note that the course aspect pertaining to the teacher specifically asks students to direct feedback on their didactic approach. As noted, students’ evaluations of teaching can sometimes be prone to unconstructive abusive comments. By explicitly asking students to focus on the didactic approach, we hope to discourage these type of undesirable and unconstructive comments.
From the list of aspects, students are asked to select just one or two key aspects which they appreciated (i.e., tops), and one or two key aspects which they think could be improved upon (i.e., tips). With this design feature, we hope counter the threat of evaluation fatigue that is more likely to occur in more comprehensive surveys like the traditional SET that require students to evaluate each and every aspect of a course.
Figure 1. Screenshot of the first step in the FET survey where students are asked to select course aspects to give feedback on.
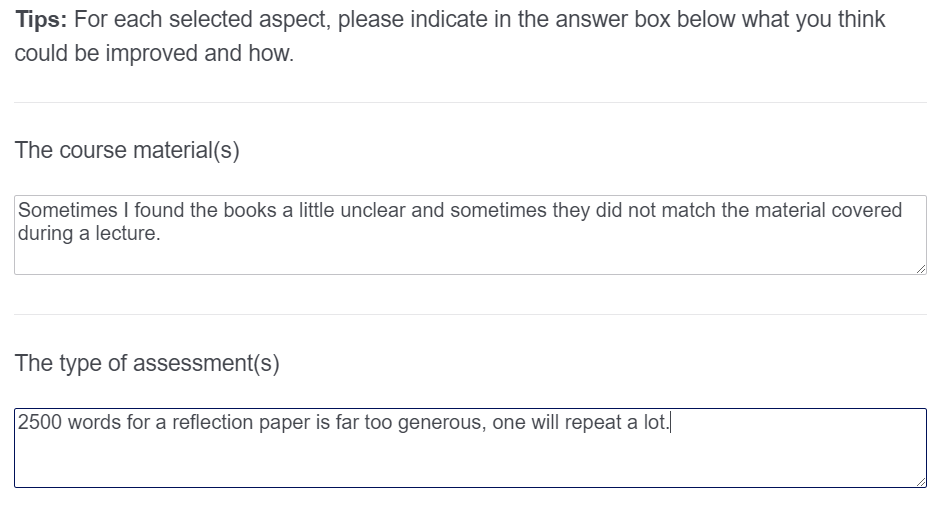
In the second step (Figure 2), after selecting one or two aspects as tips and tops, students are asked to write a short motivation for their respective selections. This set-up allows students to share their insights in a fast, efficient, and meaningful way.
Figure 2. Screenshot of FET step 2 where students are asked to elaborate on their selections.
After a given course has been evaluated, the FET output provides teachers with a ranking of aspects that were selected most frequently. Because selected aspects have also been enriched with qualitative textual input from students, teachers can engage in a focused review of those student contributions that are most relevant for improving their course (i.e., comments on aspects that were selected most frequently).
Going over the FET evaluation results should be a relatively straightforward task for those who teach small classes. However, for teachers with larger classes we anticipated that this could be a considerable burden. This is where AI comes into play. LLInC developer Erwin Veenstra and data analyst Arian Kiandoost worked on a way of complementing the raw data with an AI-generated summary of the main results. Specifically, we wanted to select a Large Language Model (LLM) that was capable of performing the task of summarizing the data in such a way that it is easy to process and interpret. We expected that, with the current level of sophistication of available LLMs, it should be possible to generate a high-quality descriptive summary of the qualitative data. It took a fair amount of experimentation, iteration, and team discussion about different possible LLMs, output formats, and the “right” prompt before we arrived at a model and approach capable of performing the task.
The LLM we ended up using was OpenAI’s GPT-4 API (OpenAI Platform, n.d.). Note that, in contrast to the non-API consumer service ChatGPT, the OpenAI API does not have the same privacy and security issues. That is, data sent to the OpenAI API is not used to train or improve the model. Still, because we ended up using a cloud-based LLM, the data were first anonymized before feeding it to the LLM. Also, we rearranged the survey data into a JavaScript Object Notation (JSON) format (JSON, n.d.) to make it easier for the LLM to group information per course aspect. The LLM was prompted in such a way that it recognized comments were grouped per course aspect, and that differences in magnitude should also be expressed in the summary (i.e., one Tip versus 10 Tops should not carry the same weight). Furthermore, we prompted the LLM to generate one synthesized integrated summarization for the tips and tops per course aspect. We found that this way of reporting helped to make explicit and nuance apparent contradictions in the data (e.g., half of the students stating one thing, the other half stating the opposite). After the summary was generated, any omissions in the output due to anonymization would be transformed back into the original values in the final report.
In the AI-generated summary, course aspects are presented in a descending order starting with the one that was selected most frequently. For each aspect, a short summary is generated to capture the overall gist of the student comments. Figure 3 shows a screenshot of an AI-generated summary and for one aspect, the working groups, of a course. Note that the summary only gives a descriptive synthesis of the students’ positive and negative, but the actual interpretation is left to the teacher. As is common knowledge, LLMs can sometimes be prone to “hallucinations”. We noticed that prompting the model to also provide an interpretation of the data, beyond what was in the text, increased the occurrence of hallucinations and also decreased the degree of reproducibility of the results. However, a simple more bare-bones LLM-generated descriptive summary provided what we felt was an accurate and reproducible representation of the data. To be sure, we prompted the LLM to supplement each summary with up to six “representative examples” (i.e., actual instances of student feedback) of tips and tops as a reference to the actual data. Furthermore, in the introduction text of to the AI-generated report, we encouraged teachers to cross-check with the actual raw data that was provided along with the summary, in case doubts would arise about the reliability.
Figure 3. Screenshot of an AI-generated summary for one of the course aspects in the FET (shared with permission from the participating teacher).
In the past couple of months, the FET has been piloted in different contexts at Leiden University, ranging from small-group settings such as an elective master class course (+-20 students) to a large-group setting such as a BA course (200+ students). The feedback from the participating teachers has been overwhelmingly positive. All teachers indicated wanting to use the FET again in the future and in their interactions with us, they were able to give multiple concrete examples of changes they intended to make in future iterations of their course. Based on the large BA course, the median time it took students to fill out the survey was around 2 minutes and 40 seconds, a duration we consider not to be too much of a burden for the students. Compared to the regular SET survey from a previous cohort, the FET survey produced much more qualitive student feedback in terms of the total number of student comments. Furthermore, although the average word count per comment that not differ much between the SET and the FET, students filling out the FET clearly put more effort into comments specifically directed at improving the course (i.e. Tips). Most important, after receiving and discussing the report, the participating teacher indicated having a high-degree of confidence in the reliability of the AI-generated summary based on cross-checking with the raw data. In short, the preliminary results of our small scale pilot suggest that the FET can be a valuable tool for efficient collection of high-quality student feedback that is formative and more conducive to the improvement of teaching practices.
Outreach activities (workshops and presentations about the FET project) have now spiked the interest in the FET project within the university. In the next phase, we hope to get further support and funding to scale up the project and see if we can replicate our findings in a broader range of contexts and faculties. Also, for future direction, we aim to use an LLM that can be run on a local server (e.g., Mistral AI, n.d., Meta-Llama, n.d.). To run the larger versions of these kind of models, we need a more powerful computer than the one we had access to during the current project. However, such a machine has recently become available at LLInC.
As the project enters the next phase, we aim to investigate how the FET survey can be successfully implemented to improve educational design and how it can support teachers professional development activities. Furthermore, in our future endeavors we plan to also take into account the student perspective. This was outside the scope of the current project, but it is vital to consider the student perspective if the project is going to move forward and scale up.
Lastly, In the FET we purposefully chose to collect only qualitative data. As already noted abusive comments can sometimes enter into qualitative evaluation data and this can cause stress and anxiety among teachers. However, the qualitative evaluation data from our small-scale pilot did not seem to contain any student comments that could be considered abusive. Perhaps this was due to the design of the FET and the phrasing of the aspects in the list from which students could choose. Or perhaps it was simply due to the fact that students were aware that they were participating in a pilot project. However, even if abusive comments would enter into the FET, we expect that the LLM should be capable of filtering out such unconstructive comments. This is one thing that we would also want to test in the future (e.g., by contaminating evaluation data with a preconstructed set of abusive comments, and training the model to filter the data).
In conclusion, we believe the FET allows teachers to collect valuable feedback on the efficacy of their teaching in a fast, efficient, and meaningful way. Furthermore, the FET holds the potential for enhancing and enriching existing teacher professionalization activities as it can facilitate critical reflection on one’s own teaching practice.
References
Harrison, R., Meyer, L., Rawstorne, P., Razee, H., Chitkara, U., Mears, S., & Balasooriya, C. (2022). Evaluating and enhancing quality in higher education teaching practice: A meta-review. Studies in Higher Education, 47, 80-96.
Heffernan, T. (2022). Sexism, racism, prejudice, and bias: A literature review and synthesis of research surrounding student evaluations of courses and teaching. Assessment & Evaluation in Higher Education, 47, 144-154.
Hendry, G. D., & Dean, S. J. (2002). Accountability, evaluation of teaching and expertise in higher education. International Journal for Academic Development, 7, 75-82.
Hounsell, D. (2003). The evaluation of teaching. In A handbook for teaching and learning in higher education (pp. 188-199). Routledge.
Reynolds, D. V. (1977). Students who haven’t seen a film on sexuality and communication prefer it to a lecture on the history of psychology they haven’t heard: Some implications for the university. Teaching of Psychology, 4, 82–83.
Stroebe, W. (2020). Student evaluations of teaching encourages poor teaching and contributes to grade inflation: A theoretical and empirical analysis. Basic and applied social psychology, 42, 276-294.
Uijtdehaage, S., & O’Neal, C. (2015). A curious case of the phantom professor: mindless teaching evaluations by medical students. Medical Education, 49, 928-932.
Uttl, B., White, C. A., & Gonzalez, D. W. (2017). Meta-analysis of faculty’s teaching effectiveness: Student evaluation of teaching ratings and student learning are not related. Studies in Educational Evaluation, 54, 22-42.
This month, the 10th Diversity & Inclusion Symposium took place, organized by the Diversity & Inclusion Expertise Office and the Faculty of Archaeology. For the small ICLON delegation that attended, the event highlighted how the questions, challenges and opportunities we face are not dissimilar to those experienced by colleagues elsewhere in our organization.
After 10 years of D&I policy, it has become clear that addressing equity, diversity and inclusion in meaningful and impactful way remains challenging. The symposium’s plenary speakers highlighted how the university is a place not just for research and knowledge sharing, but also where students and staff must learn to navigate complex and conflicting conversations. At ICLON, this is a topic that has been very much on our mind lately, as researchers, but also as teacher educators and trainers, and as an organization more broadly. How can ICLON research keep addressing these challenges? And what aspects of research and education should be emphasized in in order to contribute to an inclusive society?
Untold stories and questioning
The theme of the symposium was “Untold Stories.” In her opening keynote, Dr Valika Smeulders from the Rijksmuseum demonstrated how the museum navigates complex conversations effectively using heritage and fragile pasts. She explained about breaking existing frameworks and dominant narratives through multi-perspectivity and personal stories. In times of polarization, heritage can function to facilitate an open dialogue but also be a trigger for a heated debate.
This notion underpinned our recent research published in a history education journal. Collaborating with the Rijksmuseum van Oudheden, we developed a training for history teachers on addressing sensitive topics. Using concrete heritage objects and varied questions, teachers created space for students to share their perspectives and tell their stories. Following the intervention, teachers felt better-equipped to navigate such conversations in their classrooms, as observed in lessons addressing contentious issues like “Zwarte Piet”. Students and teachers were stimulated to ask questions. Certain questions can ‘heat up’ cooled down issues and hot topics can be ‘cooled down’ by questioning and not focusing on ‘the right answer’.
Maintaining such dialogue and continuing to question can be difficult. In a workshop at the same symposium, by Ruben Treurniet from Civinc, participants engaged with each other anonymously using a tool that connects individuals with differing views. Through an online chat session, we exchanged thoughts on statements like “Debates about academic freedom should also involve the possibility of defending the right to not be inclusive.” A slight majority disagreed with this statement. The app encouraged us to ask each other questions, and provided an intriguing opportunity to converse with someone outside of one’s usual ’bubble’.
These anonymous discussions can foster some form of connection, and can be a useful tool in developing mutual understanding. In our professional context, however, we do not generally communicate through anonymous chat, but through face-to-face encounters, with their accompanying tone, body language and emotional load. Conversations on controversial topics can become tense and confrontational, and can actually reinforce relationships of power and dominance. Explicitly expressing feelings, doubt and judgments can also be also daunting for educators and researchers expected to exude authority, or who are anxious about repercussions if they do not maintain a ‘neutral’ standpoint. However, it is important that we, as researchers and educators, demonstrate the art of doubt and model how to deal with uncertainty.
Interdisciplinarity and positionality
Finally, it may be beneficial to revisit certain cooled-down topics to practice interdisciplinary thinking and multi-perspectivity. A historical perspective, as shown by Valika Smeulders, can offer various narratives, demonstrating how history is a construct accommodating diverse viewpoints. An issue that is ‘hot’ in the present could be ‘normal’ in the past and vice versa. Looking beyond your own time and discipline can be inspiring and helpful. Collaborating across disciplines broadens perspectives while requiring us to clarify our own viewpoint through questioning and being questioned. At the moment, this principle is being applied in ongoing research with history and biology teacher trainees.
Other current projects at ICLON are exploring culturally sensitive teaching, linguistic diversity, approaches to inclusion, and teacher, student teacher and teacher educator perspectives on equality, equity and social justice. These sensitive areas of research can create vulnerable situations for participants and researchers alike. They demand researchers’ critical awareness of their positionality, grappling with their values and giving space to non-dominant perspectives, while also contributing to authoritative knowledge and relevant practical applications.
Perhaps interdisciplinary and positionality could be a theme for a future symposium, bridging the diverse perspectives, experiences and expertise at ICLON and the university more widely. We could show what ICLON can offer regarding questioning, dealing with discomfort and interdisciplinarity, and open space for further dialogue at our university.
Logtenberg, A., Savenije, G., de Bruijn, P., Epping, T., & Goijens, G. (2024). Teaching sensitive topics: Training history teachers in collaboration with the museum. Historical Encounters, 11(1), 43-59. https://doi.org/10.52289/hej11.104
Recently NWO release a new funding call for educational innovation projects, labelled “Scholarship of teaching and Learning”. This is an interesting funding opportunity for academics who would like to strengthen their teaching. Academic teachers can apply for funds to put their innovative teaching ideas into practice. And indeed this is a good opportunity to get your funding for those teaching ideas you have been waiting to implement. This also is the time to re-think your teaching and teaching ideas and put them to the test.
How often have you referred to a teacher as ‘good’ or ‘bad’ in your school career? When assessing teacher quality, we often struggle with subjective judgments and varying criteria. Is a teacher considered good because they explain well? Or because the teacher’s students obtain high scores? Perhaps it depends on positive evaluations from students. In this research blog, we aim to redefine the way we assess the quality of university educators and propose a shift toward embracing teacher agency. We argue that educators should be seen as experts in their field, who can not only meet the needs of students but also foster innovation. Educators’ willingness to take responsibility and contribute to institutional progress can significantly foster a transformative educational environment. In this regard, educators transcend their traditional role as mere providers of education and instead become facilitators of educational innovation and development.
Shortcoming of current methods
The current methods of assessing the quality of university educators have been widely criticized. For instance, several studies raise concerns about the interpretation and usefulness of Student Evaluation of Teaching (SET) ratings. These studies revealed that SET ratings were significantly influenced by students’ perceptions of their educators, thereby calling into question the validity of this specific assessment tool (see Shevlin et al., 2000 and Spooren et al., 2013 for examples).
There are also educational concerns, for example, that current assessment methods do not contribute to educators’ professional development. Among other things, assessment methods are often criticized for providing little or no constructive feedback. Without this, educators may find it difficult to improve their teaching methods or address weaknesses. Moreover, critics argue that current assessments often fail to take into account the teaching context, such as subject matter, class size, level (bachelor’s or master’s), and student diversity and background. Each of these factors can significantly affect teaching methods and outcomes and should be considered when assessing educators. Moreover, current assessment methods neglect broader purposes of teaching, such as the value of mentorship and creating an inclusive learning environment.
In some institutions, however, there is already a focus on a more holistic approach that integrates different sources of feedback, such as peer evaluations and self-reflection, to gain a more accurate understanding of teacher effectiveness, for example during the University Teaching Qualification track. The ability to reflect on what works and what does not work, and to understand why, is invaluable to teacher quality. Therefore, universities play a crucial role in promoting these skills, as these skills must be recognized and valued by policy makers by reflecting them in assessments. A change to holistic assessment of educators emphasizes effective teaching and the long-term effect educators can have on student growth. Educators need to actively pursue their own development and make informed choices in any given situation, highlighting the significance of teacher agency in discussions about teacher quality.
Embracing Teacher Agency
Embracing teacher agency in the evaluation of teacher quality is crucial for fostering a culture of innovation, growth, and student-centered education. Teacher agency refers to the ability of educators to make intentional choices and take purposeful actions in their teaching practice. It involves educators’ capacity to initiate and control the learning environment, make informed pedagogical decisions in any given situation, and collaborate with colleagues and students. Teacher agency is often seen as a key factor in promoting effective teaching and learning in higher education. By recognizing and valuing teacher agency, universities can tap into the expertise and unique perspectives of their educators.
Moreover, teacher agency encourages continuous professional development. When educators have the autonomy to explore and experiment with different instructional strategies, they are more inclined to seek out new research, attend workshops, collaborate with colleagues, and reflect on their own teaching practices. This proactive approach to professional growth ultimately benefits both educators and students, as it promotes a culture of lifelong learning and innovation within the educational institution.
Embracing teacher agency also cultivates a sense of trust and collaboration between faculty members and administration. Rather than imposing rigid evaluation criteria, universities can create opportunities for open dialogue, feedback, and collaboration, allowing educators to take an active role in shaping their own professional growth and the overall direction of the institution.
Conclusion
In conclusion, embracing teacher agency is a powerful facilitator for elevating teacher quality in universities. By empowering educators to exercise their expertise, make informed decisions, and engage in continuous professional development, universities can foster a dynamic and student-centered educational environment that nurtures innovation, growth, and excellence in teaching and learning. It is essential to engage in an active debate about the assessment of educational quality and challenge the predominant reliance on quantitative evaluations such as SET. Recognizing the complexity of assessing teacher quality, we propose a paradigm shift towards valuing teacher agency in universities. By fostering a culture that empowers educators, promotes collaboration, and encourages continuous learning, we can unlock the potential for lasting educational reforms. Embracing teacher agency is crucial for assessing educators’ quality effectively. By involving educators in the assessment process and valuing their expertise, autonomy, and professional judgment, we can create a more meaningful evaluation system. Practically, this can be achieved through collaborative goal setting, self-reflection and self-assessment, peer observations and feedback, diverse assessment methods, and continuous professional development. By recognizing educators as professionals and empowering them to take an active role in their own assessment, we create a comprehensive and empowering process that benefits both educators and students. Embracing teacher agency thus not only benefits individual educators, but also fosters an educational environment characterized by its dynamic and student-centered nature. It promotes innovation, encourages growth and strives for excellence in both teaching and learning. And that’s what we call: good teaching!
References
Biesta, G., Priestley, M., & Robinson, S. (2017). Talking about education: Exploring the significance of teachers’ talk for teacher agency. Journal of curriculum studies, 49(1), 38-54.
Cherng, H. Y. S., & Davis, L. A. (2019). Multicultural matters: An investigation of key assumptions of multicultural education reform in teacher education. Journal of Teacher Education, 70(3), 219-236.
Harris, A., & Jones, M. (2019). Teacher leadership and educational change. School Leadership & Management, 39(2), 123-126.
Imants, J., & Van der Wal, M. M. (2020). A model of teacher agency in professional development and school reform. Journal of Curriculum Studies, 52(1), 1-14.
Kusters, M., van der Rijst, R., de Vetten, A., & Admiraal, W. (2023). University lecturers as change agents: How do they perceive their professional agency?. Teaching and Teacher Education, 127, 104097.
Shevlin, M., Banyard, P., Davies, M., & Griffiths, M. (2000). The validity of student evaluation of teaching in higher education: love me, love my lectures?. Assessment & Evaluation in Higher Education, 25(4), 397-405.
Spooren, P., Brockx, B., & Mortelmans, D. (2013). On the validity of student evaluation of teaching: The state of the art. Review of Educational Research, 83(4), 598-642.
Tao, J., & Gao, X. (2017). Teacher agency and identity commitment in curricular reform. Teaching and teacher education, 63, 346-355.
Welke onderwerpen vinden docenten geschiedenis gevoelig? Enkele jaren geleden is deze vraag aan 81 docenten geschiedenis uit Nederland voorgelegd. Wat speelt in hun lessen? Op welke manier is dat gevoelig, en voor wie?
Veelgenoemde thema’s waren; a) verschillen en conflicten tussen islamitische en niet-islamitische mensen, b) kolonialisme en c) de Tweede Wereldoorlog en Holocaust. Een kwart van de docenten gaf aan geen enkel thema als gevoelig te ervaren. Volgens docenten worden onderwerpen gevoelig doordat leerlingen sterke en tegengestelde meningen in de les naar voren brengen. Daarnaast noemen ze de emotionele betrokkenheid van leerlingen en de angst om leerlingen te kwetsen. Soms ligt de aanleiding voor gevoeligheid bij de wens van docenten om een onderwerp op een objectieve manier vanuit meerdere perspectieven te bespreken. Dat wordt niet altijd goed ontvangen door leerlingen. Tot slot wordt de onverschilligheid van leerlingen genoemd, bijvoorbeeld rond het thema kolonialisme en oorlog.
Docenten verklaarden voornamelijk dat de sociale en religieuze identificatie van leerlingen een rol speelt bij de gevoeligheid van de onderwerpen. Dit bleek uit uitspraken als ‘kruistochten worden door leerlingen uit het Midden-Oosten gezien als voorafspiegeling van westerse inmenging in het MO’ of ‘leerlingen met een moslim achtergrond voelen zich hier ongemakkelijk bij’.
Wat speelt er rond het thema Islam?
Naar aanleiding van deze uitkomsten waren we van mening dat het thema ‘lesgeven over de Islam’ nader onderzoek verdiende. Er is nog weinig zicht op de complexiteit van ervaringen van docenten met Islam gerelateerde vraagstukken. Daarom zijn er interviews afgenomen met zes docenten geschiedenis met verschillende achtergronden en werkend in verschillende contexten (wel/niet islamitisch). Docenten is gevraagd om te reflecteren op de uitkomsten van de vragenlijst. En er zijn open vragen gesteld over hun omgang met dit onderwerp in de klas en hen is een casus voorgelegd.
Alle docenten herkenden de gevoeligheid rond dit thema maar gaven tegelijkertijd aan dat ze in hun eigen onderwijs geen belemmeringen ervaarden. Docenten benadrukten ook het gevaar van een eenzijdig en een ongedefinieerd gebruik van de termen Islam en Moslims waardoor de diverse percepties rond dit thema onderbelicht blijven.
Drie dimensies
Factoren die een onderwerp gevoelig maken zijn erg afhankelijk van de betrokken personen. Persoonlijke waarden, opvattingen en identiteit van leerlingen en docenten, ingebed in een maatschappelijke context, kunnen zorgen voor complexe situaties in een klaslokaal. Daarbij zijn er veel verschillen tussen individuen en is het afhankelijk van tijd en plaats en context. Om deze complexiteit en de ervaringen van de geïnterviewde docenten te ontrafelen gebruikten we drie dimensies.
De eerste, meest voor de hand liggende, overkoepelende dimensie betreft de interpersoonlijke relatie tussen docent en de leerlingen. Nabijheid op deze dimensie is een belangrijke voorwaarde voor het creëren van een veilig klimaat voor het bespreken van gevoelige onderwerpen. Anderzijds kan er ook afstand worden gecreëerd in de relatie tussen docent en leerlingen als er grenzen en normen bewaakt moeten worden.
De tweede dimensie betreft de mate waarin docenten en leerlingen een gedeelde identiteit ervaren. Maatschappelijke en religieuze identificaties die docenten niet delen met hun leerlingen kunnen ongemakkelijk zijn. Daarnaast moeten docenten afwegen hoeveel ze van hun eigen identiteit delen met leerlingen en in welke mate ze een neutrale positie kunnen behouden. (Nationale) historische verhalen hebben een identiteitsvormende functie. Verhalen kunnen gevoelens van verbondenheid creëren maar ook buitensluiten en afkeer oproepen. Verschillende perspectieven op een historisch narratief kunnen dus botsen met een behoefte aan een gedeeld verhaal, waarin ook een docent niet geheel onafhankelijk kan zijn.
De derde dimensie betreft de mate waarin leerlingen en docenten dezelfde bronnen van kennis gebruiken bij het construeren van bovengenoemde verhalen over het verleden. Vanuit deze dimensie kan de gevoeligheid van een onderwerp geduid worden door verschillen in brongebruik en de manier waarop deze bronnen gebruikt worden. Met betrekking tot de Islam is er bijvoorbeeld weinig of eenzijdige kennis in de lesboeken. Daarnaast kunnen leerlingen en docenten bronnen van kennis verschillend benaderen, wat voor spanningen in de klas kan zorgen. Verschillende omgang met bronnen kan spelen bij complottheorieën, fake news en de spanning tussen wetenschap en religie.
Waar staan de zes docenten?
Over het algemeen bleken de dimensies bruikbaar om de uiteenlopende percepties en ervaringen van docenten in kaart te brengen. We kregen zo een genuanceerder beeld van mogelijke gevoeligheden rond islam-gerelateerde kwesties in verschillende contexten.
Op interpersoonlijk vlak viel op dat docenten nabijheid creëren door persoonlijk contact en betrokkenheid maar ook bewust afstand bewaren zodat leerlingen de kans krijgen om hun eigen meningen te ontwikkelen. Docenten benoemden hierbij ook verschil in context (onder- en bovenbouw).
Uit de analyse bleek dat docenten zich bewust waren van hun verschillende identiteiten en hier flexibel mee konden omgaan en bepaalde aspecten deelden met hun leerlingen. Eén van de docenten kon bijvoorbeeld zijn eigen achtergrond (Moslim, regionale identiteit en migratie) inzetten in de klas. Het onderscheid tussen religieus/niet-religieus en Islamitisch/niet-Islamitisch bleek niet echt aan de orde te zijn bij het typeren van deze dimensie.
Met betrekking tot brongebruik gaven alle docenten aan op een kritische manier met bronnen om te gaan. Drie docenten ervaren dat ze dit delen met hun leerlingen (vooral bovenbouw), terwijl de anderen wat meer afstand ervaarden met betrekking tot het brongebruik van leerlingen. Deze docenten ervaren ongemak door het onkritisch gebruik van (religieuze) bronnen door leerlingen.
De zes docenten zijn op verschillende manieren te positioneren op de dimensies, sterk afhankelijk van het onderwerp en de context waarin ze lesgeven. We denken dat bewust omgaan met deze dimensies docenten kan helpen met het balanceren tussen afstand en nabijheid en hun eigen positie daarin. We denken ook dat de kennisdimensie explicieter aan de orde kan worden gesteld.
Vervolg
In de lerarenopleiding verkennen we verdere mogelijkheden om met deze dimensies docenten in opleiding bewuster te maken van de mogelijkheden om gevoelige onderwerpen bespreekbaar te maken. Vooral op het gebied van brongebruik zijn we aan het ontdekken hoe verschillende bronnen van kennis vanuit verschillende benaderingen kunnen worden bevraagd. Een voorbeeld is een onlangs begonnen project waarbij we docenten geschiedenis en biologie vanuit hun vak perspectieven controversiële thema’s zoals evolutie en gender laten bevragen. Daarover in een volgende blog meer.
Verder lezen:
Savenije, G. M., Wansink, B. G. J., & Logtenberg, A. (2022). Dutch history teachers’ perceptions of teaching the topic of Islam while balancing distance and proximity. Teaching and Teacher Education, 112, [103654]. https://doi.org/10.1016/j.tate.2022.103654
Op 20 april wordt tijdens het jaarlijkse conferentie van American Educational Research Association (AERA) een invited symposium gehouden over ‘educational leadership’ op initiatief van de Vereniging voor Onderwijs Research (VOR) divisie Beleid & Organisatie. Vier interessante papers worden besproken allemaal met een andere invalshoek op onderwijskundig leidershap; formeel leiderschap, informeel leiderschap, gericht op innovatie gericht op persoonlijke groei; Allemaal onderdelen van leiderschap.
LOL en SKO
Onderwijskundig leiderschap staat steeds meer in de aandacht zowel in onderwijsonderzoek als bij het opleiden van docenten. Het concept lijkt iets te bevatten waar we als onderwijsonderzoekers, onderwijsadviseurs, en docent trainers hebben gemist of altijd al hebben gezocht. Om veranderingen in het onderwijs echt te laten slagen is leidershap nodig, en dat leidershap hoeft niet altijd direct gerelateerd te zijn aan formele leiderschapsposities. Evenzo is persoonlijk leiderschap nodig om te groeien en je eigen werkzaamheden te veranderen. De leergang Onderwijskundig leiderschap (LOL) is een expliciete uiting van het vormen van leiderschap in onderwijs. De Leergang wordt in Leiden aangeboden vanuit het Leiden-Delft-Erasmus verband. Het doel van de leergang is “het ontwikkelen van een brede en praktijkgerichte visie op onderwijs en onderwijsvernieuwing bij de deelnemers.” Onderwijskundig leidershap begint kennelijk bij het inzicht hebben in je eigen visie op onderwijs en daarop reflecteren. Daarmee is het niet vreemd dat ook bij de Senior Kwalificatie Onderwijs (SKO) staat visievorming en onderwijsvernieuwing centraal. Vooral ook de invloed die de kandidaat heeft op collega’s in en buiten het eigen instituut wordt gezien als een indicator voor senioriteit en leiderschap.
Conceptualiseren
De manier waarop wij ‘leiderschap’ conceptualiseren lijkt de belangrijkste factor die van invloed is op hoe wij onderwijsverandering en onze eigen groei ervaren. Effectief onderwijskundig leiderschap binnen ondersteunt en stimuleert onder andere samenwerking, collectief leren en het opbouwen van gedeelde referentiekaders binnen de organisatie. Het uitbreiden van ons begrip van leiderschapsvormen kan helpen om de voortdurende verandering in onderwijs te ondersteunen en te stimuleren. Daarmee is dit concept interessant om verder te verkennen in onderzoek naar didactiek en het leren van docenten.
In het symposium zullen door de sprekers verschillende vormen van leiderschap in onderwijs besproken worden, zoals transformationeel leiderschap, inclusief leiderschap, gedistribueerd leiderschap en gedeeld leiderschap. Ook zullen diverse contexten en onderwijsorganisatievormen langskomen. Welke vorm van leiderschap, welke organisatiecultuur, welke structuren en welk HR-beleid het meest geschikt zijn, hangt sterk af van de actoren, context en doel. In elke context zijn verschillende variabelen, zoals overtuigingen, attitudes, vaardigheden, en mogelijkheden van doorslaggevend belang in relatie tot welke vorm van leiderschap en welke leiderschapsstructuur gewenst is.
Teacher agency
Ik raad het iedereen aan die interesseert in onderwijsvernieuwing en docentontwikkeling om kennis te nemen van dit symposium. Teacher agency, leren van docenten, pedagogical content knowledge, kennisbasis van docenten; ik kan me bijna geen onderwerp voorstellen die besproken is in onze onderzoeksgroep, die niet op een of andere manier gerelateerd is aan ‘leiderschap in onderwijs’.
Do you sum questions of your exams to get final scores of students? Do you use a questionnaire with likert-scales? Do you analyze these questionnaires by taking the means of these questionnaire-items? Do you use the mean of questions in evaluation-forms? Do you average response times to items in experimental settings?
If you have answered yes to any of these questions, you may (or may not but should) have wondered whether the items in your questionnaire, exam, test, or experiment are (sort of) measuring the same thing, the construct you had intended to be measured. If so, it is more than likely that you have calculated Cronbach’s alpha and (if the value was over .7) happily reported that indeed, the items were internally consistent. If so, you have calculated and reported the wrong measure and you are not alone. Despite the fact that methodologists have shown numerous time that Cronbach’s alpha is not suitable for measuring internal consistency (see Sijtsma, 2009, for instance), in handbooks Cronbach’s alpha can still be found as the prime choice measure to be calculated. Because the intention of questionnaire and test constructers is to summarize the test by its overall sum score, Jelle Goeman (and myself) advocate summability, which is defined as the proportion of total “test” (questionnaire-subset, exam, evaluation) variation that is explained by the sum score.
Our paper recently came out in the journal Educational Measurement: Issues and Practice, in which we show summability to be a stable measure across a number of variables (including test or questionnaire length). From the few examples that have been calculated until now, and from insight in the mathematic formula, we can assume that a summability of .5 can be considered “high”. As yet, however, more experience has to be gained on summabilities of tests in various fields before definite recommendations can be given.
Therefore, I end this blog with a “Call for Calculations”: please go to (https://sites.google.com/view/summability) and calculate summability yourself, for an existing test, exam, questionnaire, or experiment. You can download the R-code from the website, or use the link to the shiny-app. All you need is a table with items as columns and participants as rows, filled with participants’ scores on the items, supposedly measuring your (one) construct. The table can be in plain text-format or it can be an SPSS-file. Report your scores through the form available on the website. In this way, we will be able to gain a fast accumulation of knowledge of what constitutes “high,” “moderate,” and “low” summabilities. Thank you!
De universitaire lerarenopleidingen (ulo’s) liggen onder vuur. Dat is niet voor het eerst. De oorzaak voor dit terugkerende verschijnsel is dat het opleiden van docenten – net zoals onderwijs in het algemeen- simpel lijkt, maar het niet is. De meest recente discussie over kwaliteit van de ulo’s lijkt zich toe te spitsen op het onderzoek in de opleiding. Nu de postgraduate opleiding niet doorgaat – waarin geen onderzoek als eindwerk was opgenomen- staat het onderzoek in de masteropleiding weer onder druk. Het zou geen masterniveau hebben of kunnen hebben, is het verhaal. Nu is er zoals geschreven altijd discussie, maar het wordt menens wanneer beleidsmakers zich ermee bemoeien, en helemaal wanneer de politiek dat doet.
Waarom leren doen van onderzoek?
Deze gedachten worden gevoed door opvattingen wat onderzoek in een universitaire opleiding zou moeten zijn. Hierbij wordt het onderzoek vergeleken met de masterthese in een vakmaster, Onderwijsstudies of Pedagogiek. Maar deze masters zijn gericht op studenten die zich ontwikkelen tot wetenschappelijk onderzoeker in een bepaald domein. De ulo is een academische beroepsopleiding die studenten opleidt tot docenten die in staat zijn hun onderwijs te onderzoeken en op basis daarvan te verbeteren. Ofwel het primaire doel van het onderzoek in de ulo is niet het genereren van kennis, maar het verbeteren van de onderwijspraktijk.
Drie soorten kennis nodig
Wellicht kan het onderscheid van Cochran-Smith en Lytle (1999) in drie soorten kennis hierbij van dienst zijn. Het verwerven van deze drie soorten kennis speelt een cruciale rol in het leren van het beroep van docent:
• Knowledge for practice – alle kennis en inzichten over schoolvakinhoud, leren en instructie, pedagogiek, etc. die is gebaseerd op wetenschappelijk onderzoek en theorievorming.
• Knowledge in practice – alle kennis en inzichten over dezelfde onderwerpen, maar nu gebaseerd op praktijkervaringen en (kritische) reflecties op die praktijk.
• Knowledge of practice – alle kennis en inzichten die zijn opgedaan door onderzoek naar de eigen onderwijspraktijk en die van collega’s, met als doel meer te weten te komen van een bepaalde praktijk, waarbij kennis uit wetenschappelijk onderzoek wordt toegepast en als spin-off ook wordt vermeerderd.
Knowledge for practice leren studenten in de cursusonderdelen die worden verzorgd in het opleidingsinstituut, knowledge in practice tijdens de begeleide praktijkervaringen in school en knowledge of practice in het onderzoek dat de studenten tijdens de opleiding doen. Hiermee vormt het onderzoek in de lerarenopleiding ook een natuurlijke brug tussen de inzichten die worden opgedaan op het opleidingsinstituut en de ervaringen in de schoolpraktijk als docent.
Hoe ziet dat onderzoek eruit?
Dat betekent dat het onderzoek van studenten in de lerarenopleiding is ingekaderd door inzichten die zijn verkregen door wetenschappelijk onderzoek en eerdere theorievorming, maar ingegeven door vragen die zij zelf hebben over hun onderwijspraktijk. Tevens moet het onderzoek zodanig zijn opgezet dat het informatie oplevert die studenten helpt bij hun onderwijspraktijk. Effectstudies met (quasi-)experimentele onderzoeksdesigns of grootschalig surveyonderzoek mogen in veel wetenschappelijk onderwijsonderzoek usance zijn, voor een docent-in-opleiding levert dergelijk onderzoek dikwijls weinig aanwijzingen op om de onderwijspraktijk te verbeteren. Probleemanalyse, actie-onderzoek of ontwerponderzoek leveren vaak wel de benodigde informatie op en doen niets af aan het masterniveau van het onderzoek. Integendeel, het lijkt simpel, maar dat is het niet.
Dus
Stop met onzinnige vergelijkingen en ga aan de slag met de specifieke eisen die het opleiden van docenten stelt.
Don’t take my word for it, but being a scientist is about being a skeptic.
About not being happy with simple answers to complex problems.
About always asking more questions.
About not believing something merely because it seems plausible…
.. nor about reading a scientific study and believing its conclusions because, again, it all seems plausible.
“In some of my darker moments, I can persuade myself that all assertions in education:
(a) derive from no evidence whatsoever (adult learning theory),
(b) proceed despite contrary evidence (learning styles, self-assessment skills), or
(c) go far beyond what evidence exists.”
– Geoff Norman
Why you should be a skeptical scientist
The scientific literature is biased. Positive results are published widely, while negative and null results gather dust in file drawers (1, 2). This bias functions at many levels, from which papers are submitted to which papers are published (3, 4). This is one reason why p-hacking is (consciously or unconsciously) used to game the system (5). Furthermore, researchers often give a biased interpretation of one’s own results, use causal language when this isn’t warranted, and misleadingly cite others’ results (6, 7). Studies which have to adhere to a specific protocol, such as clinical trials, often deviate from the protocol by not reporting outcomes or silently adding new outcomes (8). Such changes are not random, but typically favor reporting positive effects and hiding negative ones (9). This is certainly not unique to clinical trials; published articles in general frequently include incorrectly reported statistics, with 35% including substantial errors which directly affect the conclusions (10-12). Meta-analyses from authors with industry involvement are massively published yet fail to report caveats (13). Besides, when the original studies are of low quality, a meta-analysis will not magically fix this (aka the ‘garbage in, garbage out’ principle).
Note that these issues are certainly not restricted to qualitative research or (semi-)positivistic paradigms, but are just as relevant for quantitative research from a more naturalistic perspective (14-16).
This list could go on for much longer, but the point has been made; everybody lies. Given the need to be skeptical, how should we read the scientific literature?
Using reflective reasoning to prevent bias
Reading is simple, but reading to become informed is much harder. This is especially the case when we are dealing with scientific theories. To aid you in this endeavor I will borrow the ‘reflective reasoning’ method from medical education. It has been proven that it There is some evidence that it enhances physicians’ clinical reasoning, increases diagnostic accuracy, and reduces bias (17-19).
Step One. Pick a theory. This can be your own theory, or any theory present in the academic literature. We will call this theory the diagnosis.
Step Two. Now list all the symptoms which are typical of this diagnosis. In other words: which data/studies support the theory? The key step is to differentiate between findings in the following manner:
Which findings support the theory?
Which findings contradict the theory?
Which findings are expected given the theory, but are missing?
Why can this be helpful? Because by our nature we fixate on findings which confirm what we already believe (20). These questions can help reduce confirmation bias and give you a much more balanced perspective on the literature.
If you are not aware of any contradictory or missing evidence then take this as a sign that you might have been reading a biased section of the literature.
Step Three. In addition to the initial theory, list all alternative theories which could potentially explain the same array of findings and again list all the three types of findings, like this:
Theories
Confirming findings
Contradictory findings
Findings which are expected, but missing
Theory A
Findings 1-3
Findings 4-5
Findings 6-9
Theory B
Findings 2-5
Finding 1
Findings 10-11
Theory C
Findings 1-4
Findings 2-3, 5
Findings 6-11
Why is this step so important? Because most finding can be explained by multiple theories, just as any given symptom can be explained by multiple diagnoses. Should we only check whether a particular theory is supported by some data, than any theory would suffice because every theory has some support. In the above example, theory B and C both have the same level of supporting findings, but differ dramatically in the amount of contradictory and expected-but-missing findings.
It is a given that findings can differ in the quality of evidence they provide (from uninformative to very convincing) but also in their specificity; does a finding support only one theory, or does it fit in many models? If a theory is based mainly on findings which are also explained by other theories, it’s not a strong theory.
In the end, a theory is more than the sum of its supporting or contradicting findings. Nevertheless, carefully reflecting on the quantity and quality of evidence for any theory is an essential step for being a critical reader.
Why you should not be a skeptical scientist
No matter how critical or reflective you are, you will always remain biased. It’s human nature. That’s why you should not be a skeptical scientist by yourself.
Step Four. Invite others to take a very, very critical look at the theories you use and write about. In other words, ask others to be a ‘critical friend’. For a truly informative experience, invite them to be utterly brutal and criticize any and every aspect of whichever theory you hold dear, and then thank them for showing you how you lie a different perspective.
Luckily, there just happens to already exist an excellent platform where academics relentlessly criticize anything that is even remotely suspect. It’s called Twitter. Get on it. It’s fun and very informative.
More tips for the skeptical scientist
In addition to the reflective reasoning procedure, here are some more tips which can help you become a more critical, or skeptical, scientist. Do you have tips of your own? Please share!
Play advocate of the devil: For every finding which is used to support a theory/claim, try to argue how it can be used to contradict it and/or support a different theory.
Use these wonderful (online) tools to check: whether there is evidence for p-hacking (21), whether reported statistics such as p-values are correct (22 or 23), and whether reported Likert-scale summaries are plausible (24).
Check the repeatability of a finding: For every finding, find at least one other study which reports the same finding using the same procedure and/or a different procedure. Likewise, actively search for contradicting findings.
Doing a review or meta-analyses? Do all of the above, plus make funnel plots (25).
Read the References section.
Even if you’re not a fan, try pre-registration at least once.
Use the free G*Power tool to post-hoc calculate the power of published studies, and use it to a-priori to plan your own studies (26).
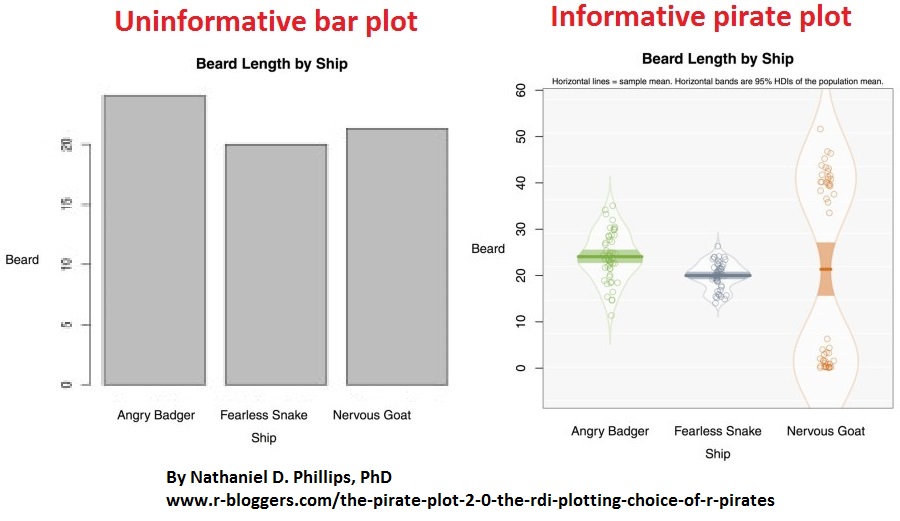
When reporting empirical data, strive to visualize it in the most informative way. Bar plots are easily one of the least informative visualizations. Use more informative formats instead, such as the pirate plot in the image below (27).
References
Dwan, K., Gamble, C., Williamson, P. R., & Kirkham, J. J. (2013). Systematic review of the empirical evidence of study publication bias and outcome reporting bias—an updated review. PloS one, 8(7).
Franco, A., Malhotra, N., & Simonovits, G. (2014). Publication bias in the social sciences: Unlocking the file drawer. Science, 345(6203), 1502-1505.
Coursol, A., & Wagner, E. E. (1986). Effect of positive findings on submission and acceptance rates: A note on meta-analysis bias.
Kerr, S., Tolliver, J., & Petree, D. (1977). Manuscript characteristics which influence acceptance for management and social science journals. Academy of Management Journal, 20(1), 132-141.
Head, M. L., Holman, L., Lanfear, R., Kahn, A. T., & Jennions, M. D. (2015). The extent and consequences of p-hacking in science. PLoS Biol, 13(3).
Brown, A. W., Brown, M. M. B., & Allison, D. B. (2013). Belief beyond the evidence: using the proposed effect of breakfast on obesity to show 2 practices that distort scientific evidence. The American journal of clinical nutrition, 98(5), 1298-1308.
Van der Zee, T. & Nonsense, B. S. (2016). It is easy to cite a random paper as support for anything. Journal of Misleading Citations, 33(2), 483-475.
Jones, C. W., Keil, L. G., Holland, W. C., Caughey, M. C., & Platts-Mills, T. F. (2015). Comparison of registered and published outcomes in randomized controlled trials: a systematic review. BMC medicine, 13(1), 1.
Bakker, M., & Wicherts, J. M. (2011). The (mis) reporting of statistical results in psychology journals. Behavior Research Methods, 43(3), 666-678.
Nuijten, M. B., Hartgerink, C. H., van Assen, M. A., Epskamp, S., & Wicherts, J. M. (2015). The prevalence of statistical reporting errors in psychology (1985–2013). Behavior research methods, 1-22.
Nonsense, B. S., & Van der Zee, T. (2015). The thirty-five percent is false, it is approximately fifteen percent. The Journal of False Statistics, 33(2), 417-424.
Ebrahim, S., Bance, S., Athale, A., Malachowski, C., & Ioannidis, J. P. (2015). Meta-analyses with industry involvement are massively published and report no caveats for antidepressants. Journal of clinical epidemiology.
Collier, D., & Mahoney, J. (1996). Insights and pitfalls: Selection bias in qualitative research. World Politics, 49(01), 56-91.
Golafshani, N. (2003). Understanding reliability and validity in qualitative research. The qualitative report, 8(4), 597-606.
Sandelowski, M. (1986). The problem of rigor in qualitative research. Advances in nursing science, 8(3), 27-37.
Schmidt, H. G., van Gog, T., Schuit, S. C., Van den Berge, K., Van Daele, P. L., Bueving, H., … & Mamede, S. (2016). Do patients’ disruptive behaviours influence the accuracy of a doctor’s diagnosis? A randomised experiment. BMJ quality & safety.
Mamede, S., Schmidt, H. G., & Penaforte, J. C. (2008). Effects of reflective practice on the accuracy of medical diagnoses. Medical education, 42(5), 468-475.
Van der Zee, T. & Nonsense, B. S. (2016). Did you notice how I just cited myself; How do you know I am not just cherry-picking? Journal of Misleading Citations, 33(2), 497-484.
Mynatt, C. R., Doherty, M. E., & Tweney, R. D. (1977). Confirmation bias in a simulated research environment: An experimental study of scientific inference. The quarterly journal of experimental psychology, 29(1), 85-95.
Duval, S., & Tweedie, R. (2000). Trim and fill: a simple funnel‐plot–based method of testing and adjusting for publication bias in meta‐analysis. Biometrics, 56(2), 455-463.
“Quest: a journey towards a goal, serves as a plot device and (frequently) as a symbol… In literature, the objects of quests require great exertion on the part of the hero, and the overcoming of many obstacles”.
From last December until now, I have been anxiously awaiting for mail in my mailbox here at ICLON. By the time it was Christmas, I was singing “All I want for Christmas, is maiiiiil”! Really, nothing could make me a happier PhD student than receiving a bunk of mail like this on my desk every week:
Because, ladies and gentlemen, my first data have arrived! Finally tangible proof that my first year of work as a PhD student has paid off.
Constructing and distributing a questionnaire was somewhat more complicated than I thought. Here are some things you should think about:
Constructing the questions. You cannot just ask whatever you fancy to ask, I discovered. You need to justify what you ask your participants, preferably supported by literature and/or by questionnaires already available covering your topic.
Online or hardcopy’s by mail? That was a very relevant question, since I wanted to have about 2000 students filling in my questionnaire, an online survey would be so much easier for me. But it would also have such a small response rate… Also considering that my questionnaire took about 20 minutes to complete, I chose to send around my questionnaire in hardcopy. That way, students could fill it out in the lesson of the corresponding teacher, and be more likely to complete the survey.
Recruit participants. In my case, I needed schools and teachers to commit to my research, ensuring their students and teachers would fill in my questionnaires. I already knew some teachers, but definitely not enough to cover my whole research population. So, I started asking around. With colleagues (do they have any contacts with schools that might be interested?), friends, acquaintances, institutions also interested in my research topic… And eventually, I even made a list of appropriate schools, looked up their telephone numbers and tried to call the specific teachers to explain them about my research and invite them to participate. Do not underestimate this step. It. Takes. Time.
Logistics. After I printed and stapled over 2000 questionnaires (thank God for automatic staplers), they needed to get to the right persons in the right schools. And those right persons in the right schools should also be able to send the piles of paper back to the right person: me! I am so, so lucky to have gotten help from people in my department, and people from the post office (and occasionally my boyfriend, who helped in the stapling process). I had this whole administration of how many questionnaires should go to which school, how many for students (white coloured paper) and how many to teachers (orange coloured paper). I needed piles of envelopes with the right addresses, and also self-addressed envelopes in which the teachers could send the questionnaires back in the mail.
Communication. It helps to be clear about the agreement you have with the corresponding teacher. Remind them in which classes the questionnaire has to be distributed. In general, remind them. And administer who returned how many questionnaires to you.
And then, everything needed to get back to me. I waited in such anxiety. At this moment, my response rates luckily seem very high, although one of my greatest fears also came true as some of the envelopes got lost in the mail. While still awaiting the very last envelopes to return, the scanning and analyses can begin…
What are your experiences when constructing and distributing a questionnaire? What were the obstacles you met, and do you have any tips and tricks for others? Please let me know in the comments below!
Please, feel free to add comments and questions to the posts by clicking on the title of the post. At the bottom you can put your comments.
Please share the post in your network by clicking on the icon (-s) below the posts.












Recent Comments